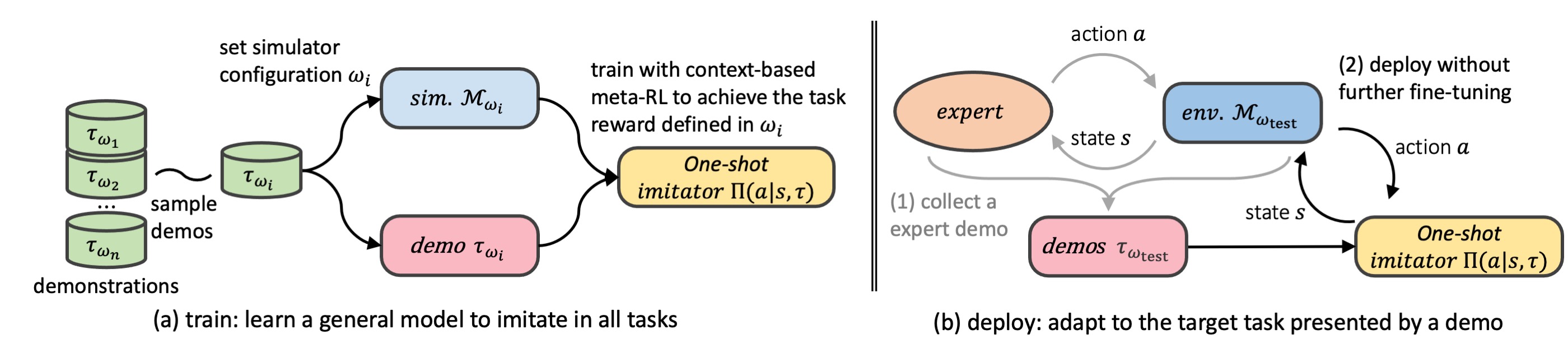
One-shot imitation learning (OSIL) is to learn an imitator agent that can execute multiple tasks with only a single demonstration.
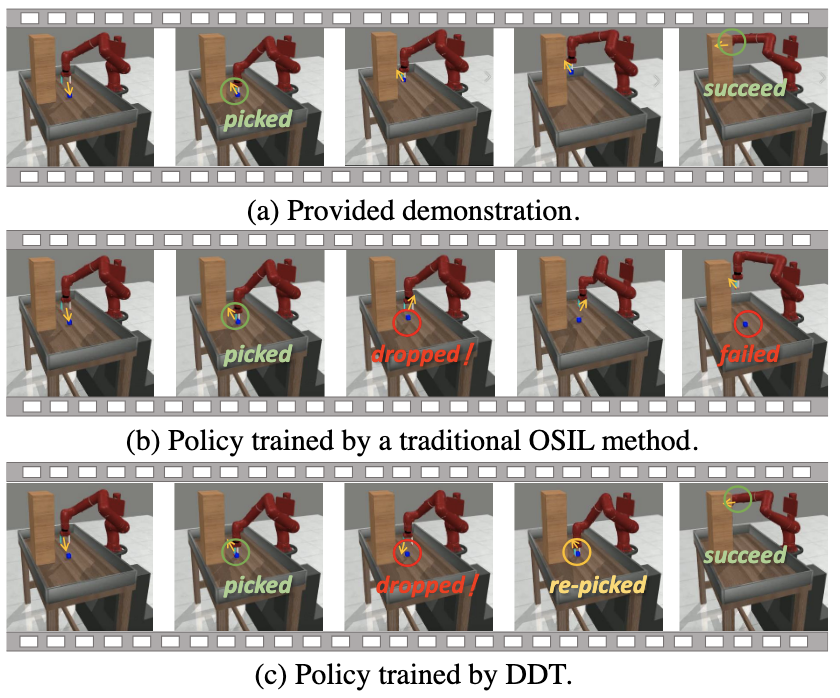
In real-world scenario, the environment is dynamic, e.g., unexpected changes can occur after demonstration.
Thus, achieving generalization of the imitator agent is crucial as agents would inevitably face situations unseen in the provided demonstrations.
While traditional OSIL methods excel in relatively stationary settings, their adaptability to such unforeseen changes,
which asking for a higher level of generalization ability for the imitator agents, is limited and rarely discussed (See the following Figure). In this work, we present a new algorithm called Deep Demonstration Tracing (DDT).
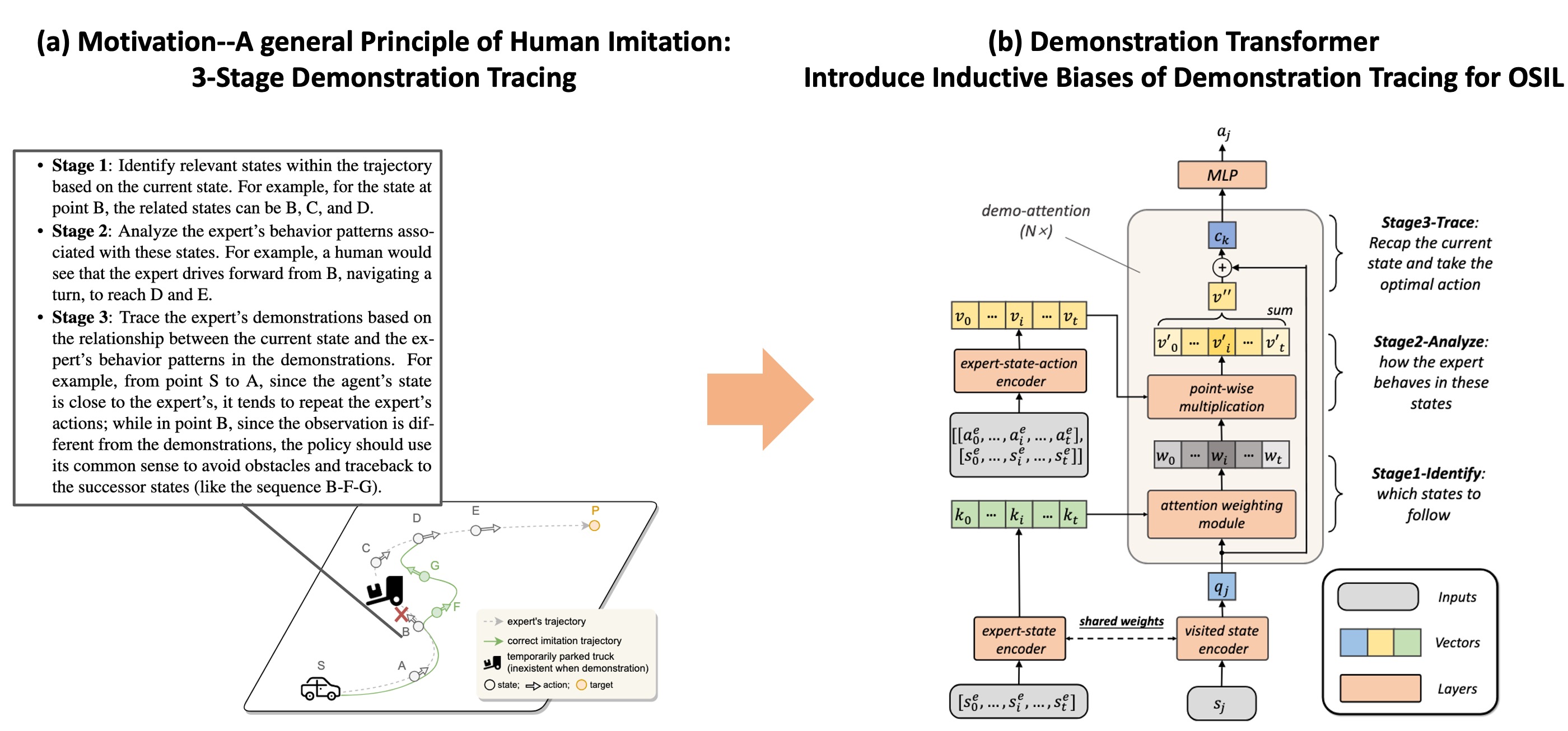
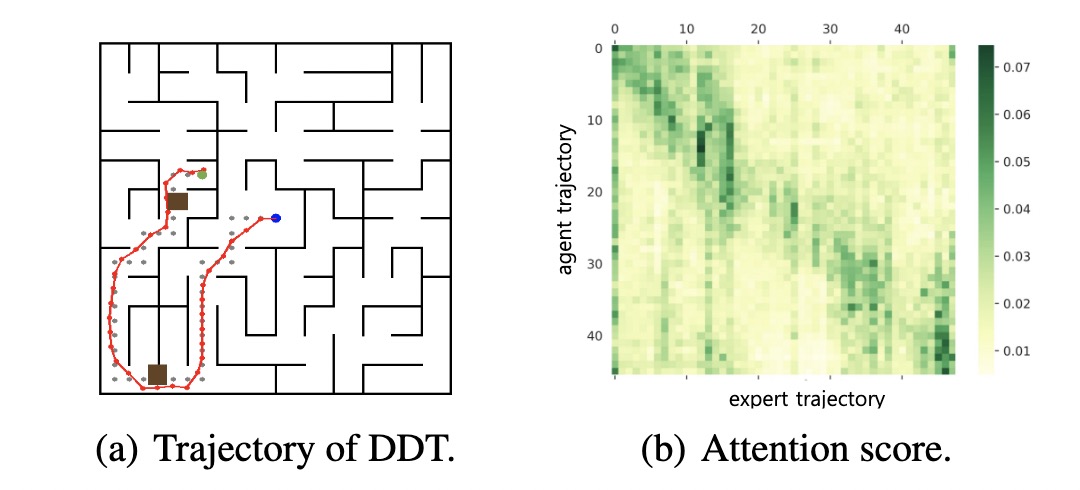
In DDT, we propose a demonstration transformer architecture to encourage agents to adaptively trace suitable states in demonstrations.
Besides, it integrates OSIL into a meta-reinforcement-learning training paradigm, providing regularization for policies in unexpected situations.
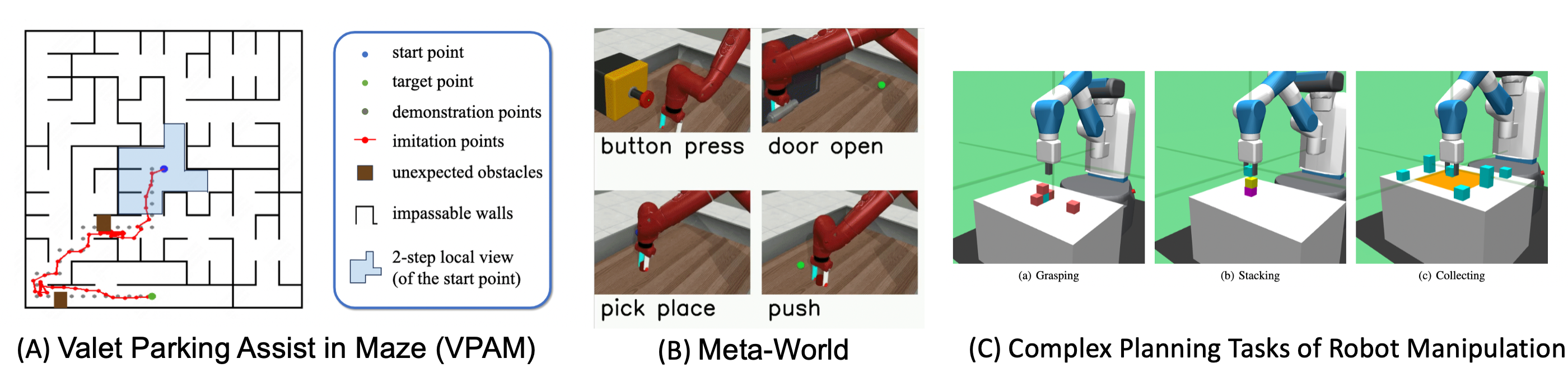
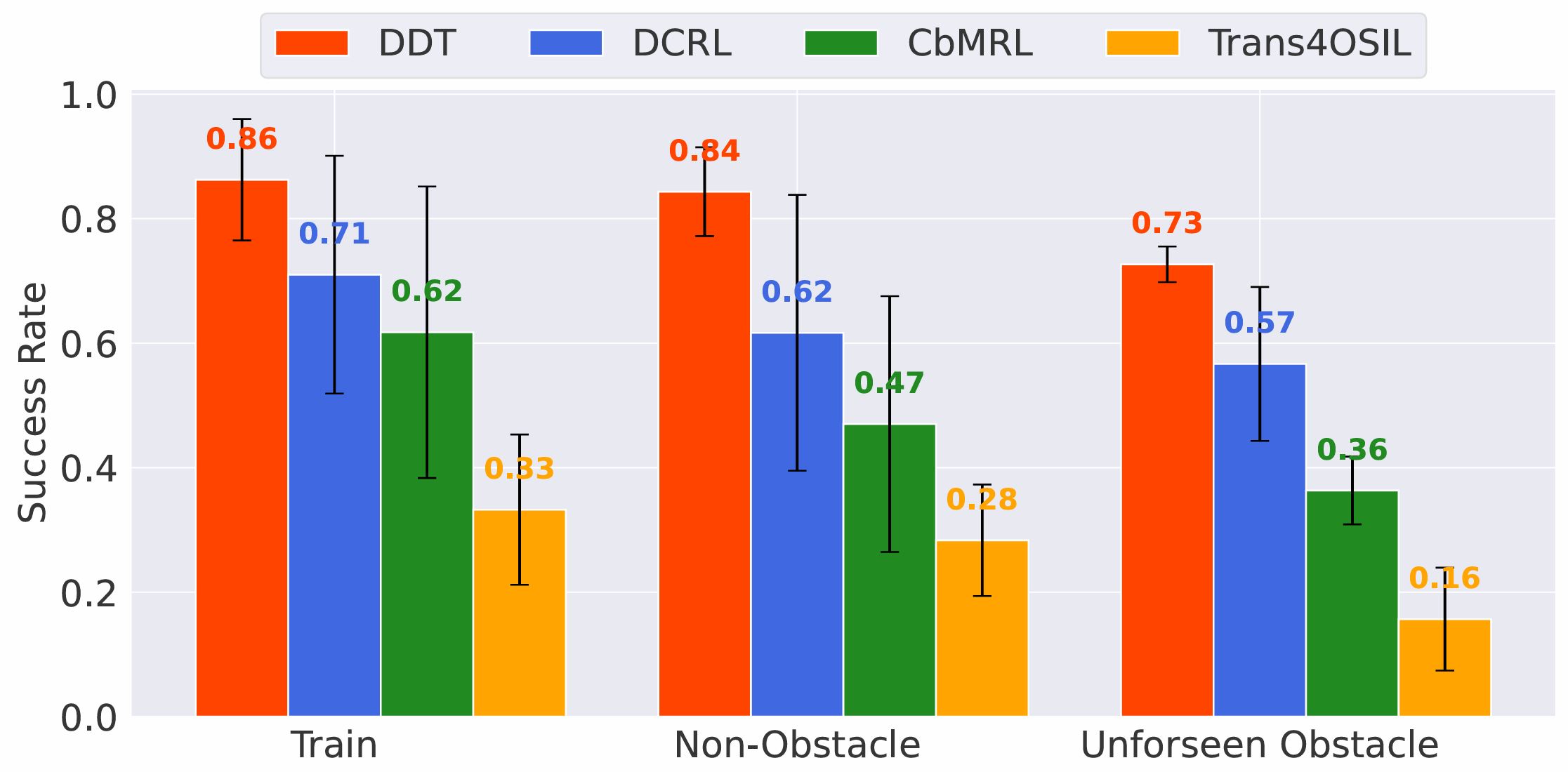
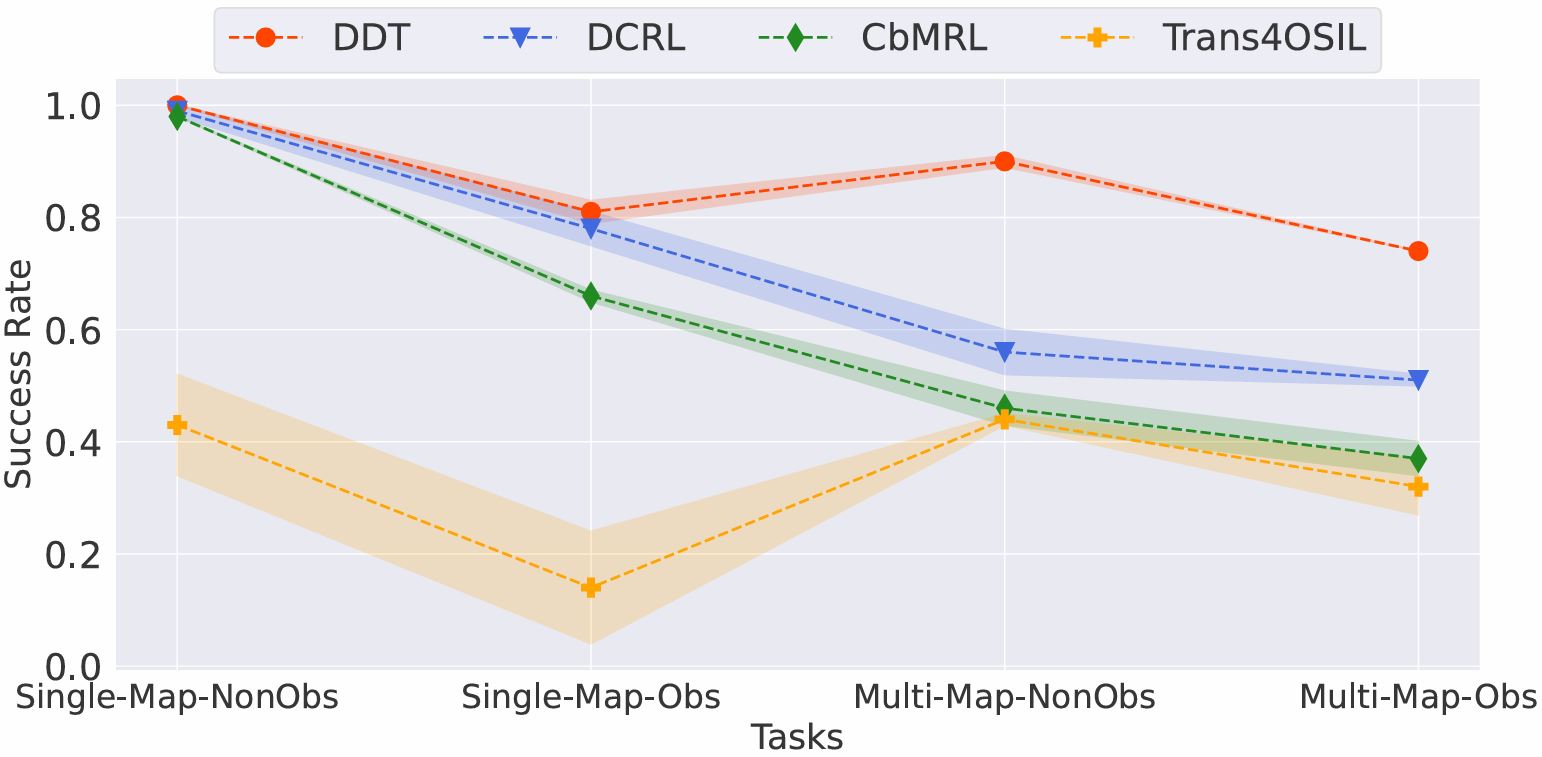
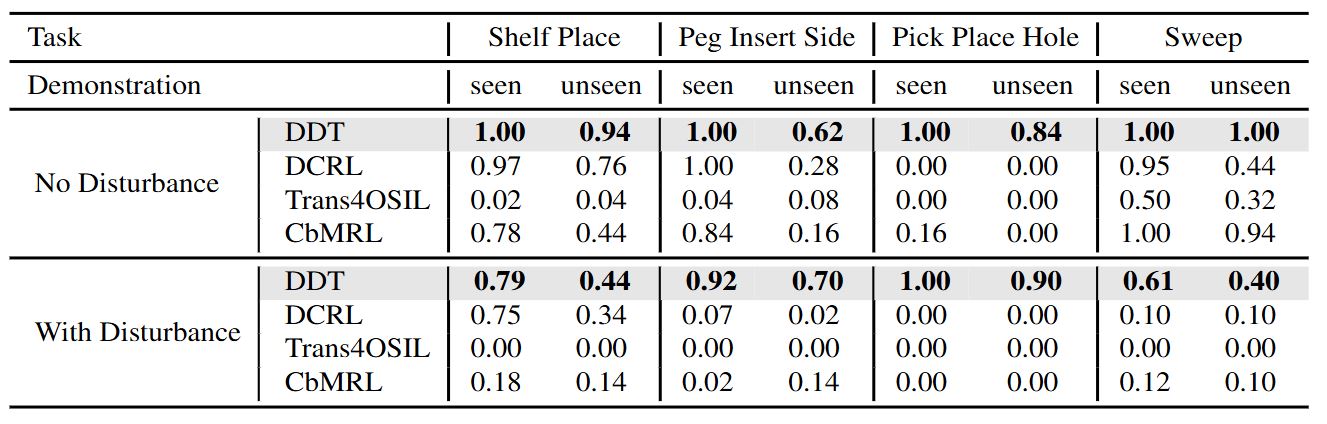
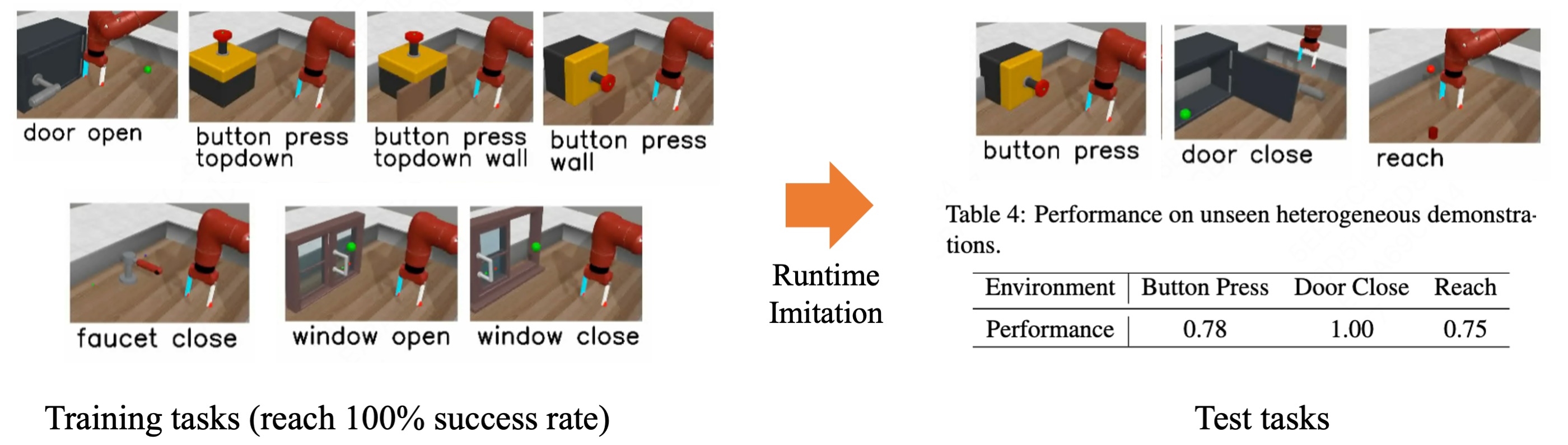
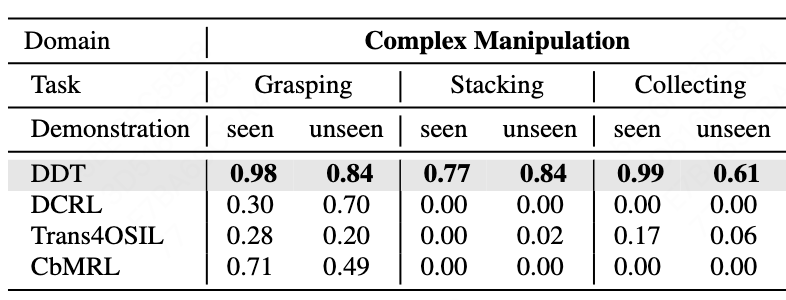
We evaluate DDT on a new navigation task suite and robotics tasks, demonstrating its superior performance over existing OSIL methods across all evaluated tasks in dynamic environments with unforeseen changes.